Note
Go to the end to download the full example code
Twin evaluation of a scalar dynamic ROM#
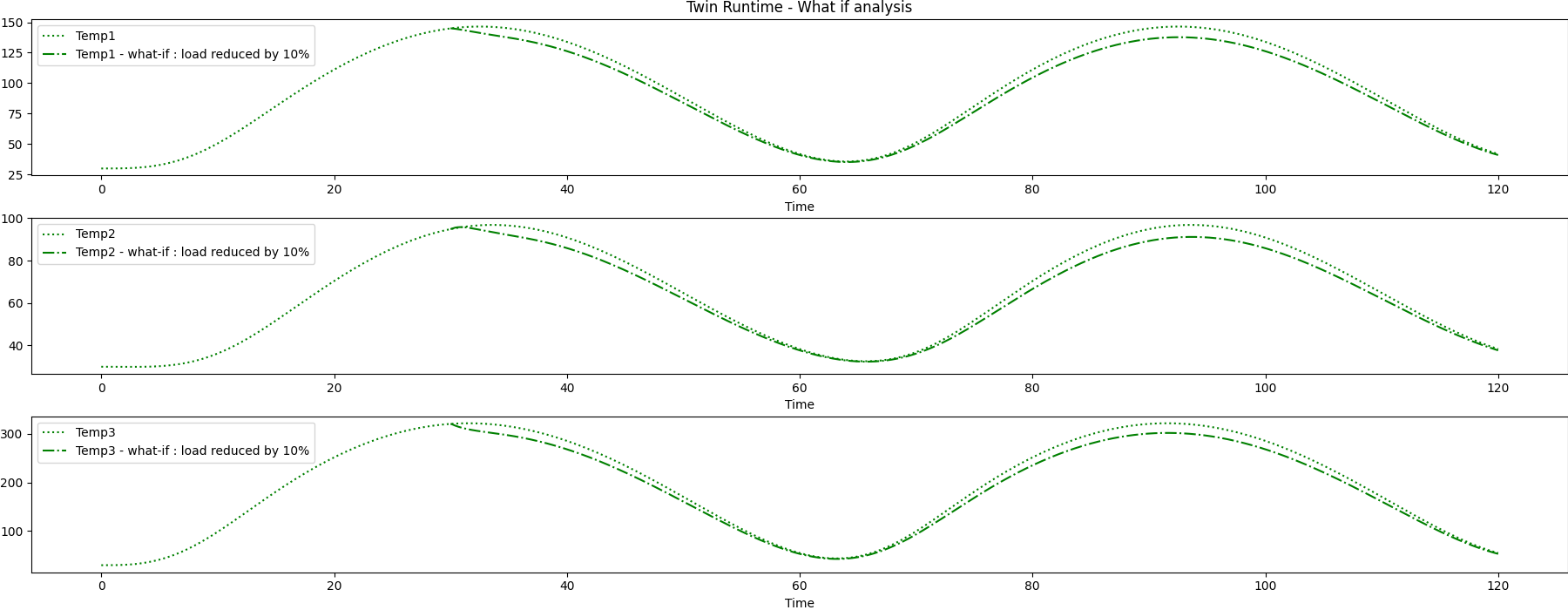
This example shows how you can use PyTwin to load and evaluate a twin model of a scalar dynamic ROM. The ROM is created from a 3D thermal model of a heat exchanger. The input is the heat flow. The outputs are the temperatures from three temperature probes. The workflow for this example performs what-if analysis by deploying a second twin in parallel while simulating the original twin so that results from the different predictions can be compared. This comparison is done using methods for saving and loading twin states. This example also shows how to change the PyTwin working directory location from the default (%temp%) to a specified location, where logging files are available.
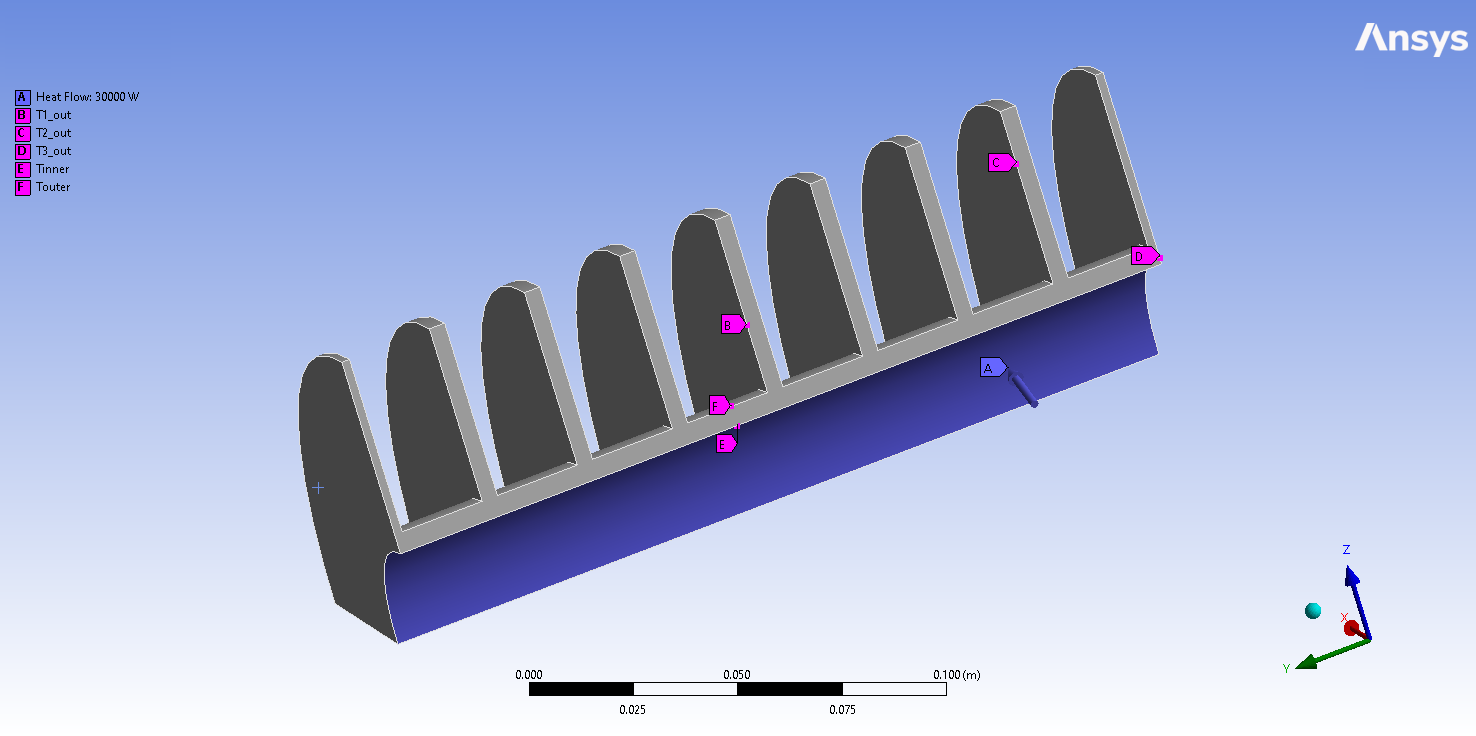
# sphinx_gallery_thumbnail_path = '_static/scalarDROM.png'
Perform required imports#
Perform required imports, which include downloading and importing the input files.
import os
import matplotlib.pyplot as plt
import pandas as pd
from pytwin import TwinModel, download_file, load_data, modify_pytwin_working_dir
twin_file = download_file("HX_scalarDRB_23R1_other.twin", "twin_files", force_download=True)
csv_input = download_file("HX_scalarDRB_input.csv", "twin_input_files", force_download=True)
Define auxiliary functions#
Define auxiliary functions for comparing and plotting the results from two different simulations executed on the same twin model.
def plot_result_comparison(step_by_step_results: pd.DataFrame, what_if: pd.DataFrame):
"""Compare the results obtained from two different simulations executed on the same
twin model. The two results datasets are provided as Pandas dataframes. The function
plots the results for all the outputs."""
pd.set_option("display.precision", 12)
pd.set_option("display.max_columns", 20)
pd.set_option("display.expand_frame_repr", False)
# Plot runtime outputs
columns = step_by_step_results.columns[1::]
columns_what_if = what_if.columns[1::]
result_sets = 1 # Results from only step-by-step + what-if analysis
fig, ax = plt.subplots(ncols=result_sets, nrows=len(columns), figsize=(18, 7))
if len(columns) == 1:
single_column = True
else:
single_column = False
fig.subplots_adjust(hspace=0.5)
fig.set_tight_layout({"pad": 0.0})
for ind, col_name in enumerate(columns):
# Plot runtime results
axes0 = ax[ind]
step_by_step_results.plot(x=0, y=col_name, ax=axes0, ls=":", color="g")
axes0.legend(loc=2)
axes0.set_xlabel("Time [s]")
# Plot twin what-if analysis results
what_if.plot(x=0, y=columns_what_if[ind], ax=axes0, ls="-.", color="g", title="Twin Runtime - What if analysis")
if ind > 0:
axes0.set_title("")
# Show plot
plt.show()
Change the working directory#
Change the working directory from the default location (%temp%) to a specified location and load the input data.
modify_pytwin_working_dir(os.path.join(os.path.dirname(twin_file), "pyTwinWorkingDir"))
twin_model_input_df = load_data(csv_input)
data_dimensions = twin_model_input_df.shape
number_of_datapoints = data_dimensions[0] - 1
Load the twin runtime and instantiate it#
Load the twin runtime and instantiate it.
Loading model: C:\Users\ansys\AppData\Local\Temp\TwinExamples\twin_files\HX_scalarDRB_23R1_other.twin
Define the inputs of the twin model and initialize it#
Define the inputs of the twin model, initialize it, and collect the output values.
Simulate the twin for each time step#
Loop over all inputs, simulating the twin one time step at a time and collecting the corresponding output values.
sim_output_list_step = [outputs]
sim_what_if_output_list_step = []
data_index = 0
while data_index < number_of_datapoints:
if data_index == int(number_of_datapoints / 4) and twin_model_what_if is None:
# Save the original model's current states
twin_model.save_state()
# Instantiate a new twin model with same TWIN file and load the saved state
twin_model_what_if = TwinModel(twin_file)
twin_model_what_if.load_state(model_id=twin_model.id, evaluation_time=twin_model.evaluation_time)
sim_what_if_output_list_step.append(outputs)
# Get the stop time of the current simulation step
time_end = twin_model_input_df.iloc[data_index + 1][0]
step = time_end - twin_model.evaluation_time
inputs = dict()
for column in twin_model_input_df.columns[1::]:
inputs[column] = twin_model_input_df[column][data_index]
twin_model.evaluate_step_by_step(step_size=step, inputs=inputs)
outputs = [twin_model.evaluation_time]
for item in twin_model.outputs:
outputs.append(twin_model.outputs[item])
sim_output_list_step.append(outputs)
if twin_model_what_if is not None:
inputs = dict()
for column in twin_model_input_df.columns[1::]:
inputs[column] = (
twin_model_input_df[column][data_index] * 0.9
) # Evaluate the second twin using the same inputs reduced by 10%
twin_model_what_if.evaluate_step_by_step(step_size=step, inputs=inputs)
outputs = [twin_model_what_if.evaluation_time]
for item in twin_model_what_if.outputs:
outputs.append(twin_model_what_if.outputs[item])
sim_what_if_output_list_step.append(outputs)
data_index += 1
results_step_pd = pd.DataFrame(sim_output_list_step, columns=["Time"] + list(twin_model.outputs), dtype=float)
outputs_names = list(twin_model.outputs)
output_names_parallel = []
for i in range(0, len(outputs_names)):
output_names_parallel.append(outputs_names[i] + " - what-if : load reduced by 10%")
results_what_if_step_pd = pd.DataFrame(
sim_what_if_output_list_step, columns=["Time"] + output_names_parallel, dtype=float
)
Plot results#
Plot the results and save the images on disk.
plot_result_comparison(results_step_pd, results_what_if_step_pd)
Total running time of the script: (0 minutes 4.034 seconds)